As we all probably know, our benevolent Bob is updating the software for LSC. These kinds of updates have risks, notably in this case around the freight sheds.
To attempt to help, I’ve created a website that will have a few utilities for use by anyone (for free). First is a way to export a complete topic (all the pages) into a single HTML page. I hope to also do a utility to download all photos from a freight shed.
The web page is available at https://lsc.jimrowson.com [link] and looks like this right now:

If you provide a url to a topic and click the button, you get a web page that looks like this:

Feel free to complain or point out bugs here. I reserve the right to work on this as much as I feel like, though. So purely visual changes may not be a high priority for me.
Cheers!
 . Click on the Print button
. Click on the Print button  . This will bring up the preview pane allowing you to see what the top of the file will look like. In the upper left corner of the preview pane, click on the print button . This will open a pane where you can choose a printer. In this pane click on ‘Microsoft Print to PDF’
. This will bring up the preview pane allowing you to see what the top of the file will look like. In the upper left corner of the preview pane, click on the print button . This will open a pane where you can choose a printer. In this pane click on ‘Microsoft Print to PDF’ 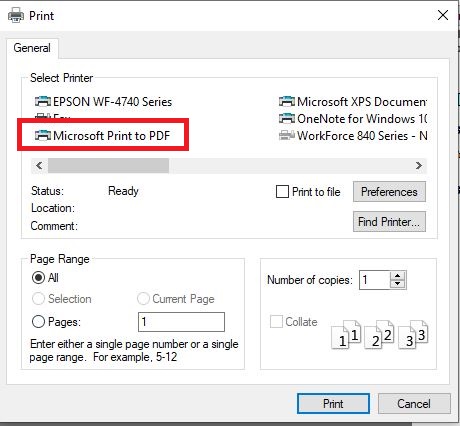 . This will then bring you to where you will give your PDF a name and choose a folder where to place it.
. This will then bring you to where you will give your PDF a name and choose a folder where to place it. , it will bring up a pane with a list of all the image files in the scrape including the path info.
, it will bring up a pane with a list of all the image files in the scrape including the path info. 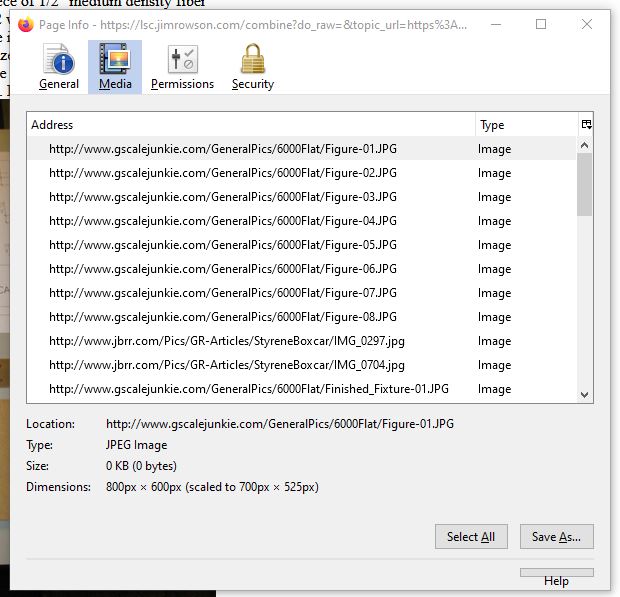 . In the image list pane, select Select All
. In the image list pane, select Select All 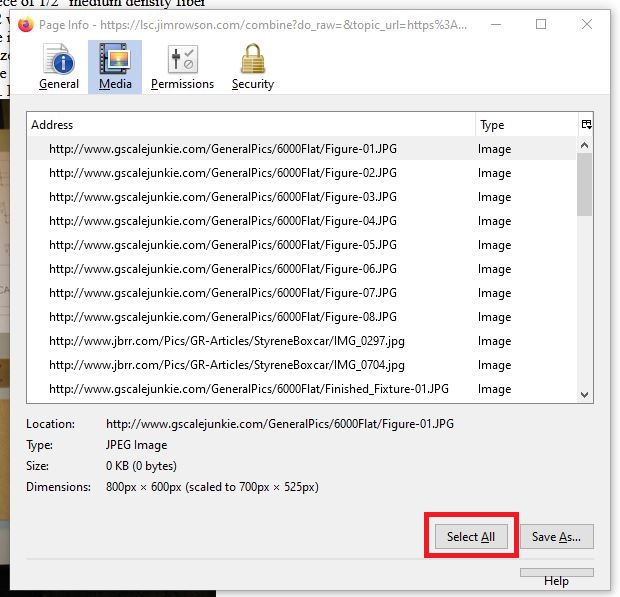 . This will get a complete list in the pane of all the images in the thread. If you wish to save the images to a local folder, choose ‘Save All’ and then choose a folder where you want to store the images. You can also save the list by right clicking in the list area which will highlight the list and bring up a small dialog box. Click Copy in the dialog box.
. This will get a complete list in the pane of all the images in the thread. If you wish to save the images to a local folder, choose ‘Save All’ and then choose a folder where you want to store the images. You can also save the list by right clicking in the list area which will highlight the list and bring up a small dialog box. Click Copy in the dialog box. 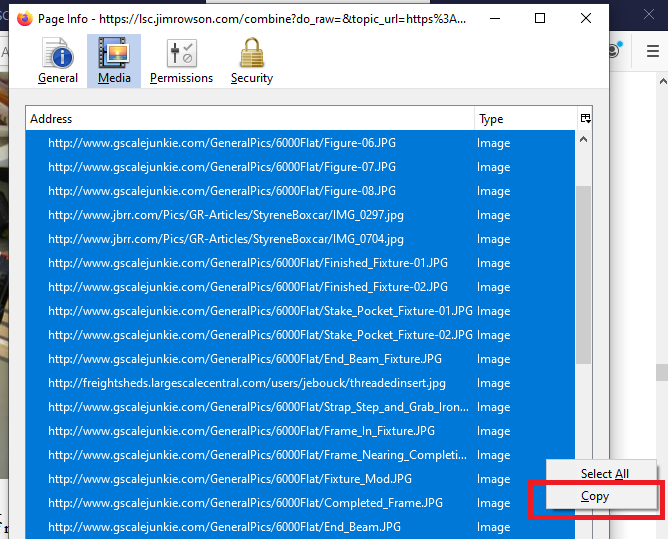 Open Note Pad or Word and paste the list into the text editor.
Open Note Pad or Word and paste the list into the text editor.



{kind=link}